Machine Learning in Real Life (Part 2)
Tales from the Trenches to the Cloud (Part 2 of 2)
So, this is the 2nd post about deploying machine learning models into production. My first post is here. I once again present to you the Overly Simplified Diagram (the OSM) of the Machine Learning Process.
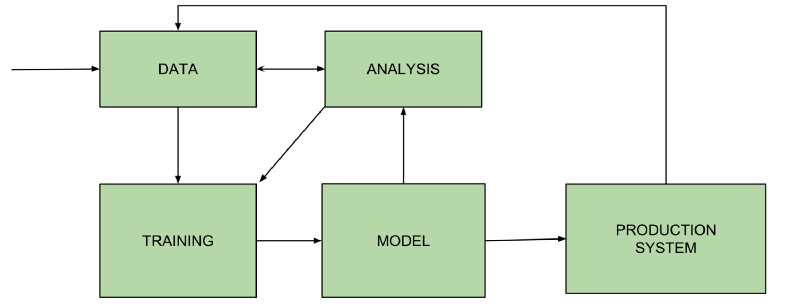
Last time, I discussed Data, Model and Training. This time, I’ll discuss Analysis and Production.
Analysis
So, to continue from last time: We have a model and it’s versioned, we’ve stored some metrics for it in a database from training, etc, etc… great! Perhaps it has an adequate enough error rate for the big boys with the trucks of pieces of green paper to give it the go ahead (they for some reason trust you utterly and completely)… and you go ahead and deploy it.
If this is your first iteration of the model, it’s highly likely you will find some weak points. Perhaps the data in production has drifted from the data you originally put together for training and now your model has gaps in it’s knowledge and behaves unpredictably when it sees things it does not know about (this becomes particularly fun in deep learning where the dimensions of the problems are substantially larger and more complex). Suppose you (or your angry client) has identified some Problem X with the model. Now what?
Let’s suppose you get more data related to Problem X and you retrain your model. (Seems reasonable, right?) Awesome! You check out your homeboy metrics and they have improved a little. Awesome… that must mean it’s solving Problem X, right?
RIGHT?!?!
Well, actually, you REALLY have no idea if it’s improved on Problem X at all. Even worse: Suppose you gave it more data related to Problem A, B and C (training is expensive, good to retrain with a bulk of improved data) and now your AUC has improved. But which of the problems have you solved and to what extent? Did it even improve on any of them tangibly? Did it improve enough for the men with the trucks of green money to let your new model loose on their upset clients again? How can they know it’s really better than the previous model? In fact, are your AUCs from experiments with totally different validation data even comparable?! No, no they’re not.
These are problems I experienced. When my client went “Have you solved this problem?” and I had to spend lots of manual time comparing previous models on a handful of ad-hoc test cases that I came up with, and could never repeat (since they were lost in jupyter notebook hell!). And each time I retrained with newer data, the process became more hellish and less scientific. And so I concluded that I’d have to buck up on my analysis. So here are my recommendations.
Automate your tests
- Like you have your unit tests run in your continuous integration tool, make your tests for every candidate model run every time too.
- Write regression tests to enforce minimum requirements are met. (Think of them as your Canary Tests).
- Build up important test patterns over time. Make sure you include tests with sample data from a production setting as well as contrived tests that you understand well.
- Continuously gather outlier patterns that break the system and add a number of related test cases, in an to attempt to understand the major problem.
- Ask your users to help rate their experience and ask the testers to add patterns to the database directly when they pick something up.
Track Progress
What do I mean by tracking progress? I mean Graphs! Bitches love graphs!
So, the most obvious one is tracking your important metrics, for each candidate model you have so far.
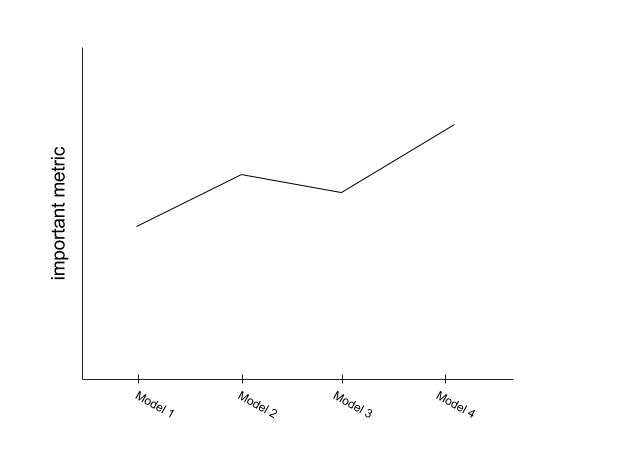
Yeah, duh! We got that one. We can now see how your models are improving over all. But now let’s think about that Problem X we spoke about earlier. Chances are, it’s not just Problem X… Upset client will pick up Problem X, Y, Z and all their friends. Maybe your image processing model can’t distinguish between Chihuahuas and muffins, or your natural language generation engine is a fascist.

Well, perhaps we should store a list of those problems in an actual database **cough**, instead of a text file, an unmaintainable, unversioned excel spreadsheet, or slack channel **cough**.
On top of that, we should probably figure out the extent of those problems, perhaps by using some production examples and amending that with contrived examples. We should take care to construct those examples carefully, since I want them to be easily examined but still capture the entire problem (So using both positive examples and negative examples).
So this is what I do, for each problem identified in the models.
- When a new problem is detected, I’d add it to the database of problems
- I identify 10–15 patterns that, when examined, would show if the model was getting better or worse (both negative and positive) on that specific problem and I add them to the database, and add a foreign key to the problem. Why 10–15? Because that is not too many to individually examine, but enough to cover a couple of versions of the problem
- Each time a new candidate model is chosen, I test those patterns, for each problem, and gather metrics overall for each problem based on the performance on the patterns. I also rerun the patterns for each problem, for each prior candidate model. The result is that I can build up the following graph:
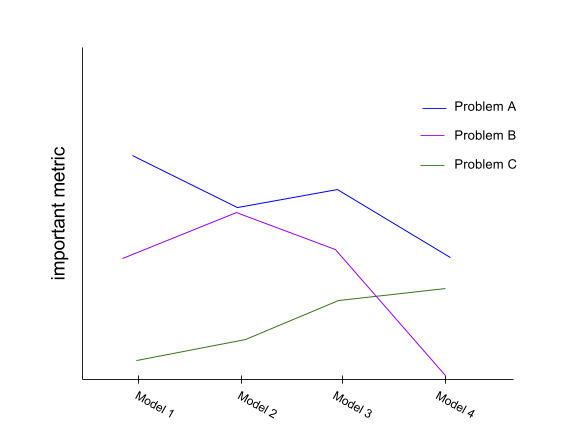
So what does that graph show? It shows an important performance metric (suppose it is error rate), for each problem, on each candidate model, over time. This means I can see how my candidate models are performing over a variety of identified issues. I can see what improvements to my data set or changes in my architecture resulted in improvements (or otherwise) on different problems. Not only that, but I can report to the men with the trucks of green paper, that I am getting a 80% accuracy on a specific problem and get sign off on that. Really really useful stuff! And kinda silly when you spend some time thinking about it.
So now that you know you got an improvement on the chihuahua to muffin problem, you might want to see which patterns improved or didn’t improve? Well, easy to do since you’ve stored this entire process in a database, and you can just query each pattern for a particular problem and examine them manually. Do this.
Production
So the guys with the green paper really want to see the model in ACTION. They’re happy with all the metrics. You’re feeling uneasy, but surprised (and maybe slightly impressed) you got this far in the first place.
Now what? Sadly, it’s unlikely you can thoughtlessly shove an API on the front of it. It is now the time to think about those non-functional requirements (in fact, we probably should have thought of this substantially earlier, but with all that business of model training, here we are!). A couple of key things to think about, just to mention a few:
- Throughput requirements — Is this a once a day job or an every couple of seconds job? Can the job take a week to complete or does it need to need to run in milliseconds?
- Scalability — So let’s say this needs to run per user. How does your infrastructure support x10 or x100000 as many users? Can it cope with a burst in activity from users. Does your problem grow exponentially as your user-base grows? If your problem grows exponentially, how will you guarantee your throughput overtime?
- Cost — Spark cluster’s are expensive. Is your client happy paying that AWS bill? If you have to cut costs, what is the impact on scalability or throughput.
What the above largely involves is thinking about what architecture and technology you will be using in production. You may have trained the model using Keras, but maybe your production requirements need SparkML. Your training data was fine sitting in one database, but the data certainly needs something more robust — maybe it needs replication. Maybe you have a massive load at certain times of the day and require something like Kubernetes to scale up your machines.
Not only that, but maybe you can do some tricks with the stuff you’ve already learnt — maybe doing some quick pre-clustering to save time later. There are some fun things here that I will expand on in a future post
Wrap Up
I hope you’ve enjoyed these posts and I hope they’ve contained some useful wisdom which can aid you on your true quest to getting those models into production. I leave you with this:
“People worry that computers will get too smart and take over the world, but the real problem is that they’re too stupid and they’ve already taken over the world.”
Pedro Domingos
