Machine Learning in Real Life
Tales from the Trenches to the Cloud (Part 1 of 2)
So I recently did a talk at the Jozi Developer User Group and I was asked to turn it into a blog post, so here it goes.
Monitoring infrastructure, machine learning and Clojure at the developer user group w/ @alienelf at @MicrosoftSA pic.twitter.com/mCuJMvo7Nh
— Jared (@binarystrike) April 11, 2017
We live in a world where everyone knows enough about the Buzzwords “Deep Learning” and “Big Data” to write shitty buzzfeed articles about (leaving this here as it will prompt another article)
On the other hand, we also live in a world where if you’re a developer you can, while knowing nothing about machine learning, go from zero to training a OCR model in the space of an hour. Give it a few more hours, and you can have yourself your very own Trump-like tweet generator.
And that is great. In fact, it’s wonderful! The world of machine learning is extremely open. New articles are published on arxiv and are immediately scrutinised by the community. Everyone is contributing to the open source libraries — of which there are hundreds in every language imaginable. If you want to try something, there are probably 10 000 tutorials of people who have done so, and all their code is available on github. Welcome to the world of open artificial intelligence. Isn’t it beautiful?
However, we have a problem. Unless you’re one of the major players (Google, Microsoft, IBM, Salesforce, Amazon), most machine learning academics or tinkerers have never taken a machine learning model into production. Machine Learning consulting is an extremely tricky (and sometimes near on impossible) business and we need to start talking about it more.
There is very little literature on the subject. And once you start working on such a system, you realise the Nietzsche essay generator you wrote in 2 hours one evening last week isn’t going to get you anywhere near solving the real problems. Here are some of the questions I got stuck on:
- Into what infrastructure do we deploy a machine learnt model?
- How do we maintain such model?
- How do we test the trained model?
- How do we scale the infrastructure around this model?
- When is a model good enough to be deployed?
- When is a model better than a prior model?
- Is my data good enough?
- If my data is not good enough, how do I make it better?
- Why is my model doing that?
- What process do we follow to improve the model and data?
Which leads me to this OVERLY SIMPLIFIED DIAGRAM or OSD as I like to call it. I will refer back to the silly OSD. It’s not a complete (or even very correct) view, but it highlights the main parts I’ve dissected this process into and will aid the discussion of the questions I have raised.
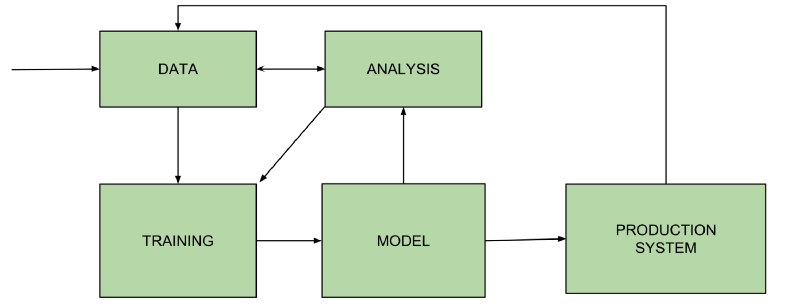
After starting to write this post, I realised it was going to go on FOREVER, so I’m breaking it into 2 parts. So looking at the OSD, in Part 1 (this post), I’ll talk about data, training and the model. In Part 2 (my next post), I’ll talk about analysis and taking the model into a production system (the fun stuff!).
For Part I, I’d like to thank THIS POST. I was plodding my way on, blindly plowing through, doing my best and that post gave me affirmation that I was mostly on the correct track and thus I have included some of it’s points in this post. I recommend that any avid machine learning enthusiast who wants to proceed doing real life machine learning work give it a go.
Data

Let’s talk about data — arguably the most important and very often, the most painful.
Is my data good enough?
Well, depending on the problem and the techniques you intend to train with, it might be, but often, data can be the most resource intensive step of the process. Gathering it, processing it, improving it, convincing clients to give you access to it.
What is BAD data?
- Data that is largely inaccurately labelled (a small percentage of inaccuracies is fine, since noise is often a good thing for models to teach them to generalize)
- Data that does not properly represent the sample where the model will eventually be used.
BUT, here is some very important news about bad data: Sometimes, bad data is all you have! Often, getting that decent data is expensive or time consuming. And getting perfect data is definitely a near-impossible feat. But bad data can sometimes get you pretty far — in fact, in many cases it can often get you 50%-80% of the way. So don’t be scared of starting out with bad data. It can likely get you on the correct direction. One of the major problems to look out for is Data Leakage which is quite horrifying
If my data is not good enough, how do I make it better?
When in doubt: You need more of it. Tools like Mechanical Turk and lots of cold hard cash to pay your human data creators. Also, it’s important to capture user interactions: Allow your users to rate your recommendations and use other interaction data (clicks or wait times) to help improve data quality. Keep in mind that it takes time to collect this sort of data, but make sure you are capturing it!
Treat your data as data
- Put it in a database (big data or relational — whatever suits). Store backups of your database
- Always store timestamps of when data patterns were added to the set. This will help you later when data patterns will likely become more irrelevant over time.
- Store the source of each data pattern. Expert-labelled data is more accurate and useful than data generated or labelled by non-experts. It is good to know what data came from where.
Training
Your training algorithm is code, so treat it as such.
By that we mean:
- Version it.
- Write unit tests for it. (Trust me on this, it’ll save loads of wasted training hours)
So, Training Results?
- After training, make sure you store your results in an actual database. Which has backups, and time stamps.
- Store your newly generated models (all of them — even the bad ones) in some sort of reliable file system.
- Have a way to trace your generated model back to the code that made it, so that you can always know what training code resulted in a particular model.
- Be able to trace a set of results (error rates, correlation coefficients, individual classification/prediction on each of your comparison/validation patterns) to the model that gave those results
- Be able to trace any generated model back to the original data and code that generated it
An actual example
In our latest solution
- We stored experiment results in a couple of tables in a database (on AWS RDS with daily backups), which not only stores the final performance metrics, but also stores links to where the generated models which we stored in AWS s3.
- We create a git tag automatically for the training code, each time an experiment is run, with the database experiment id in the git tag text. This is to tie the code that generated the model to the model itself.
- Each data pattern has timestamps so that we know when each pattern created and deactivated and so we can always determine what data resulted in what model.
- We also stored what the model outputted for each pattern in the validation/comparison set, in a queryable manner so that different models can be compared.
Model

“Treat it like a config”.
It should be versioned. It should also ideally be stored in a technology independent manner since the platform you trained on is often not the same as the platform you will deploy to production.
When is a model good enough to be deployed?
Well, depending on the application, business rarely strives for perfection — often it just wants to beat or equal it’s human counterparts. Define your performance metrics up front. Being able to agree and sign off on on a performance metric that business agrees to and understands is important — whether they be areas under the curve or mean squared errors. For example, you could say that a model is good enough when it performs 90% as well as human counterparts, or has an AUC that is 10% better than an existing expert system.
How can I trust it?
Many corporates are afraid to trust these magical machine learnt beasts. Some models (such as trees) aid themselves to being examined and confirmed by an expert, however neural networks, on the other hand, do not. Thankfully, there are groups of researchers out their building tools to enable us to understand HOW a neural network is making the decisions. These tools are called Explainers
In particular, a most useful favourite of mine is LIME. LIME is a model independent Explainer that very cleverly figures out what parts of an input pattern a model is using to predict the output. It does so by perturbing the input pattern, (sort of “greying out” areas of the pattern) in a whole load of ways and then training a model to learn how that affects the output
This picture below shows what information a specific neural network used to detect the cat in this image (the green) and what information was saying it wasn’t a cat (the red dog)

Pretty cool huh? This way, one can make sure that the neural network is not incorrectly using the snow in the background to classify Wolves from dogs, rather than the animals themselves. LIME also works on text-based input, which I’ve used extensively in my latest project
In the next episode of Machine Learning in Real Life, I will talk about the other parts missing from my OSD: Analysis and Production. Expect many graphs (MANY GRAPHS!). I hope that answers some of those burning questions you may have about building Machine Learning systems in real life.
